
Si vous travaillez proche d’environnements web, vous avez probablement déjà entendu parler de GraphQL. Et pour cause, ce langage a été créé il y a déjà près de 10 ans et est aujourd’hui un standard pour beaucoup de sociétés.
Dans la suite de cet article je vais m’atteler à simplifier le sujet afin que vous compreniez pourquoi vous devriez vous intéresser à cette technologie.
Donc si vous voulez en savoir plus sur ce langage afin de comprendre comment il pourrait se matérialiser dans votre organisation sans forcément devenir un expert.
Vous êtes à la bonne place 😉
Les bases du GraphQL
Avec le graphQL on va encore entrer dans une guerre de GAFA (oui oui encore une fois).

Le GraphQL est un langage de requêtes pour API et un environnement pour exécuter ces requêtes. Ce langage a été créé en 2012 par Facebook et rendu public en 2015.
L’objectif est d’imposer un nouveau standard dans le développer d’API (rien que ça 😅)
Besoin de précisions ? Ok je comprend, on repose les bases…
C’est quoi une API ?
API « Application Programming Interface », que l’on traduit par interface de programmation d’application.
Pour faire simple une API va permettre à des produits ou services web de communiquer.
Une bonne image des API est de les considérer comme un contrat avec une documentation qui constitue un accord entre les parties.
Il suffira d’avoir connaissance du contrat attendu par un outil tiers pour être en mesure d’échanger avec ce dernier. Si l’outil tiers partage son contrat avec tout le monde, ce sera une API public…

C’est quoi un langage de requêtes pour API ?
« Un langage de requête est un langage informatique utilisé pour accéder aux données d’une base de données ou d’autres systèmes d’information. »
Ca c’est un point important. Il permet de comprendre que les API véhiculent des données. Et que ces données sont accessibles via des requêtes un peu comme une base de données.
Pourquoi parlons-nous de nouveau standard ?
Alors là nous en revenons à la guerre des Gafa.
La communication entre des outils via des flux informatiques n’est pas nouveau. Le graphql a même de très nombreux ancêtres.
Les standards d’API
La communication entre des outils web (ou autre) a toujours existée, le problème est qu’il n’y avait pas de norme.
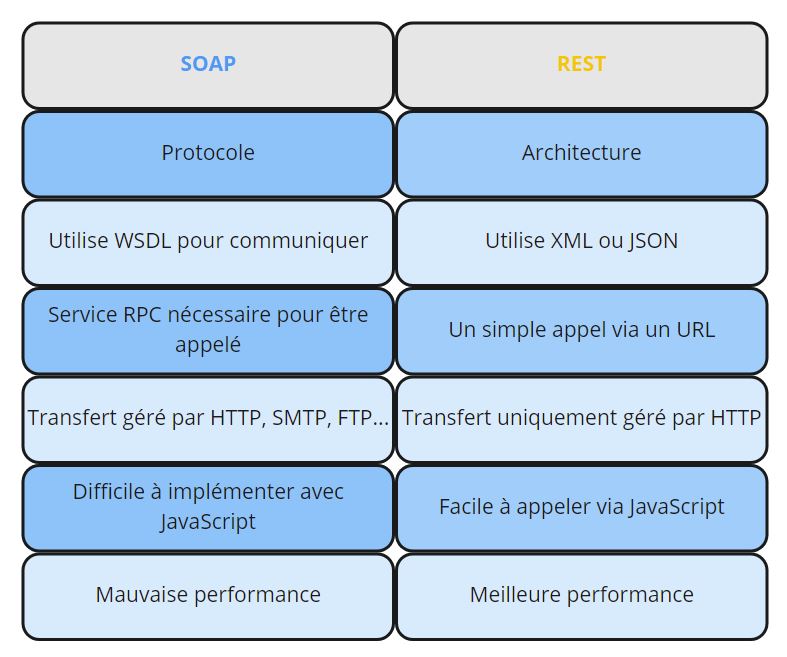
Le premier standard, est apparu avec dans les années 1990, il s’appelait SOAP le « Simple Object Access Protocol ». Ces API utilisent le format XML pour échanger leurs messages et reçoivent des requêtes via HTTP ou SMTP.
Ensuite il y a eu REST Le « Representational State Transfer » une autre tentative de normalisation.
Les API Web qui respectent les contraintes de l’architecture REST sont appelées API RESTful.
La grande différence entre les 2 est que :
SOAP est un protocole à part entière avec que REST est un style d’architecture.
Pour faire simple, Les API sont RESTful tant qu’elles respectent les six contraintes de conception d’un système RESTful :
- Une architecture client-serveur : une architecture REST est composée de clients, de serveurs et de ressources et elle traite les requêtes via le protocole HTTP.
- Un serveur sans état : le contenu du client n’est jamais stocké sur le serveur entre les requêtes. Les informations sur l’état de la session sont, quant à elles, stockées sur le client.
- Une mémoire cache : la mise en mémoire cache permet de se passer de certaines interactions entre le client et le serveur.
- Un système à couches : des couches supplémentaires peuvent assurer la médiation dans les interactions entre le client et le serveur. Ces couches peuvent remplir des fonctions supplémentaires, telles que l’équilibrage de charge, le partage des caches ou la sécurité.
- Code à la demande (facultatif) : un serveur peut étendre les fonctionnalités d’un client en lui transférant du code exécutable.
- Interface uniforme : cette contrainte est capitale pour la conception des API RESTful et couvre quatre aspects différents : Identification des ressources dans les requêtes, Manipulation des ressources par des représentations, Messages autodescriptifs, Hypermédia comme moteur du changement des états applicatifs.
Et le GraphQL est née pour révolutionner tout cela
Comme bien souvent dans les technologies web, les GAFA sont arrivés pour mettre un « grand coup de pied dans la fourmilière » !
Bon, il ne faut rien exagérer. Le GrapQL n’est pas une révolution si importante que ça.
Dans le sens où elle ne réinvente pas entièrement le système d’échange de REST mais elle vient l’améliorer.
En réalisé la seule chose qui change entre les 2 est l’API de routage.
Pour information, le rôle de cette couche dans une API REST comme dans une API GraphQL sera d’appeler des règles métiers en fonction de la requête.
L’environnement d’exécution de GraphQL n’est donc qu’une couche de routage de l’API, qui interprète des requêtes GraphQL, reçues via le payload d’un POST.
Alors qu’est ce qui change entre le REST et le GraphQL ?
Plusieurs choses vont changer dans le GraphQL.
1, GraphQL est est un langage de requêtes. Ceci va nous permettre d’être très précis quant au besoin d’information dès l’appel.
2, GraphQL et son environnement d’exécution. Cet environnement va interpréter et structure ses requêtes à partir du schéma. Ce schéma sera donc un élément central du modèle.
3, GraphQL et son resolver, Celui-ci permettra d’associer une fonction de l’API (récupération d’une donnée, lancement d’un ordre de calcul.…) à une requête ou une action définie dans le schéma.
Bref, le graphQL va permettre de créer une requête (plus structurée que le REST) afin d’obtenir une réponse directe du besoin.
Ci-dessous un exemple concret de requête GraphQL :
GET /graphql?query={ orders(id:125) { customers { firstName, lastName }, amount, orderDate }
{
Query { // operation type
orders (id:125) { // operation endpoint
customers { // requested fields
firstName
lastName
}
amount
quantity
orderDate
}
}
}Voici concrètement les avantages du GraphQL. Avec une unique requête, analysée et traitée par l’environnement d’exécution et le resolver, nous pouvons récupérer un objet et tous les objets liés.
De plus il est possible de préciser les champs de l’objet que l’on souhaite récupérer.
Dans notre exemple, pour afficher une liste de commandes triées par date de commande, il suffirait de récupérer les champs « id » et « ordersDate ».
Pour obtenir un résultat similaire en REST, il nous faudrait :
1, Faire une requête en passant le numéro de la commande
GET /orders/125Pour obtenir le détail d’une commande.
{
“customerID”: 765,
“orderDate” : 12/09/2021,
“quantity”: 15
}Pour ensuite réaliser un seconde requête REST afin d’avoir le détail de l’auteur
GET /customers/765Ce type d’exemple reflet concrètement les avantages du GrapQL par rapport au REST.
- Avec la réponse REST, tous les attributs de l’objet Orders sont récupérés même s’ils ne sont pas utile dans le contexte. Ceci augmente le trafic réseau entre le client et le serveur ainsi que la taille de la réponse.
- A la différence de la requête GraphQL, une requête REST ne retournera que le contenu de l’objet en lui même et pas les objets liés.
En conclusion, pourquoi s’intéresser au GraphQL
Avec moins de requêtes, des résultats plus légers et plus complets impliquant moins de trafic réseau et un code plus logique, GraphQL sera intéressant si votre l’application fait appel à de nombreuse requêtes.
La contrepartie sera une mise en œuvre qui peut s’avérer plus complexe et plus longue.
Un point intéressant également avec GraphQL sera sa capacité d’adaptation dans les montées de versions. En effet, en interrogeant précisément les informations voulues GraphQL se « moquera » si votre schéma s’enrichie ou se complexifie.

